Ihre Dashboards sind grün. Ihre Alerts sind still. Und irgendwo in Ihrer Microservices-Architektur baut sich ein Kaskadenausfall auf, der die Produktion um 3 Uhr morgens zum Absturz bringen wird. Traditionelles Monitoring kann dieses Szenario nicht verhindern, weil es Ihnen nur sagt, wonach Sie bereits wussten zu fragen. Observability ist anders—es lässt Sie die unbekannten Unbekannten erkunden.
Monitoring vs. Observability: Der kritische Unterschied
Monitoring dreht sich um das Sammeln vordefinierter Metriken und Alarmierung bei bekannten Fehlermodi. Sie entscheiden im Voraus, was gemessen wird: CPU-Auslastung, Speicherverbrauch, Request-Latenz, Fehlerraten. Wenn etwas außerhalb Ihrer vordefinierten Messungen fehlschlägt, ist Monitoring blind.
Observability hingegen geht darum, Systemverhalten durch seine externen Ausgaben zu verstehen. Ein beobachtbares System lässt Sie beliebige Fragen stellen, ohne neue Instrumentierung zu deployen. Der Unterschied ist am wichtigsten beim Debuggen neuartiger Probleme—die, die nicht in Ihrem Runbook standen.
Der Test für Observability: Können Sie von außen verstehen, warum sich ein System fehlverhält, ohne neue Instrumentierung hinzuzufügen?
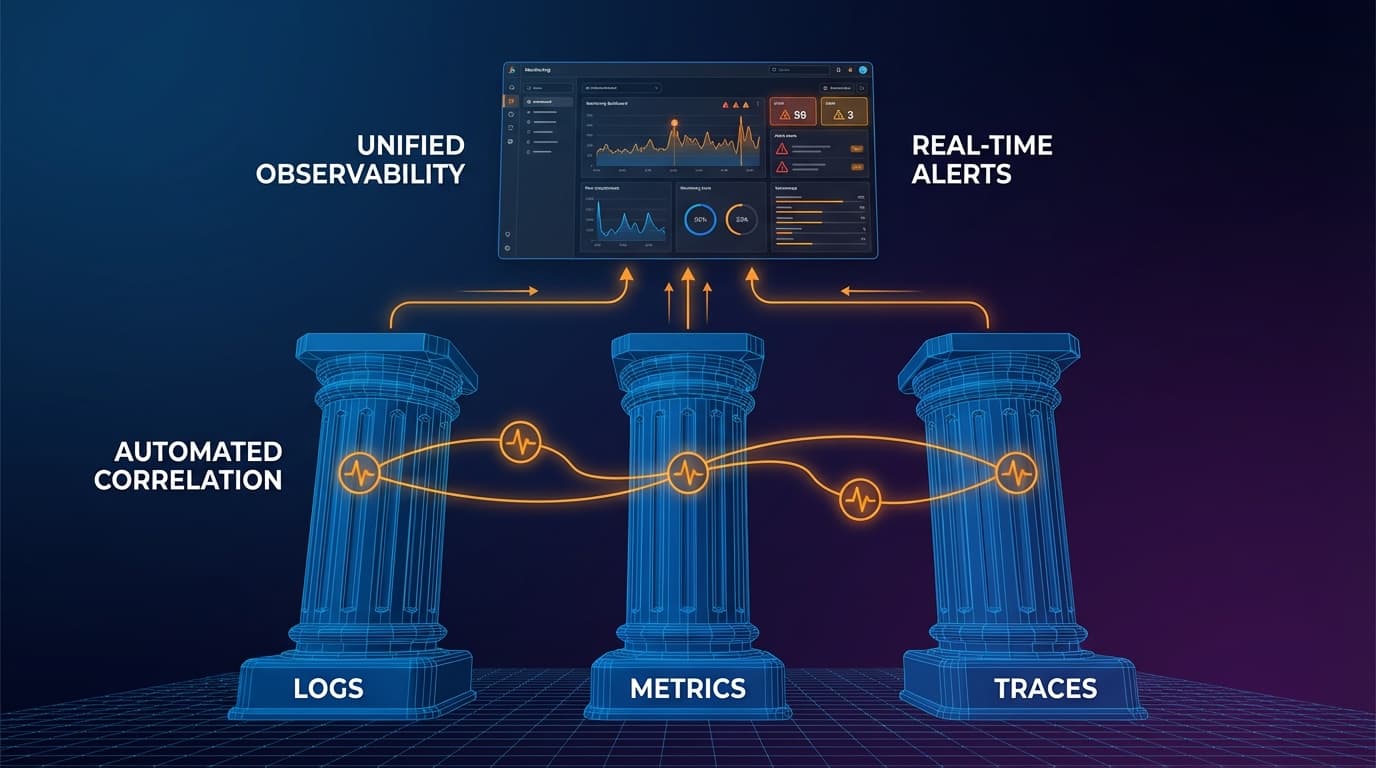
Die drei Säulen erklärt
Moderne Observability ruht auf drei komplementären Datentypen: Logs, Metriken und Traces. Jede dient einem anderen Zweck, und zusammen bieten sie umfassende Sichtbarkeit.
Säule 1: Logs
Logs sind zeitgestempelte Aufzeichnungen diskreter Ereignisse. Ein Benutzer hat sich eingeloggt. Eine Datenbankabfrage wurde ausgeführt. Ein Fehler ist aufgetreten. Logs bieten den reichsten Kontext, sind aber am teuersten zu speichern und bei Skalierung abzufragen.
Best Practices für Logs:
- Strukturiertes Logging: JSON-Format verwenden, nicht Klartext. Strukturierte Logs sind durchsuchbar und parsebar
- Konsistentes Schema: Feldnamen über Services hinweg standardisieren (timestamp, service_name, trace_id, user_id)
- Angemessene Verbosity: Debug-Logs in Entwicklung, info/warn/error in Produktion
- Korrelations-IDs: Jedes Log sollte eine Trace-ID enthalten, die es mit verwandten Events verbindet
Säule 2: Metriken
Metriken sind numerische Messungen, die über die Zeit aggregiert werden. Request-Rate, Fehlerrate, Latenz-Perzentile, Ressourcenauslastung. Metriken sind günstig langfristig zu speichern und exzellent für Dashboards, Alerting und Trendanalyse.
Die vier goldenen Signale:
- Latenz: Wie lange Requests dauern (p50, p95, p99 sind wichtiger als der Durchschnitt)
- Traffic: Wie viel Nachfrage auf Ihr System trifft
- Errors: Die Rate fehlgeschlagener Requests
- Saturation: Wie voll Ihr System ist (Speicher, CPU, Disk, Verbindungen)
Wenn Sie nichts anderes überwachen, überwachen Sie diese vier Signale für jeden Service.
Säule 3: Traces
Verteilte Traces verfolgen Requests, während sie Service-Grenzen überschreiten. Eine einzelne Benutzeraktion könnte zwanzig Microservices berühren—Traces zeigen Ihnen die gesamte Reise, mit Timing für jeden Hop.
Traces beantworten Fragen, die Logs und Metriken nicht können: Wo hat der Request seine Zeit verbracht? Welcher Downstream-Service verursachte die Verlangsamung? Wie breiten sich Fehler durch das System aus?
Tracing implementieren:
- An Grenzen instrumentieren: HTTP-Calls, Datenbankabfragen, Queue-Operationen, externe APIs
- Kontext propagieren: Trace-IDs durch alle Service-Calls weitergeben
- Intelligent samplen: Sie können nicht jeden Trace speichern—Errors bei 100% samplen, Erfolge bei niedrigeren Raten
- OpenTelemetry verwenden: Der CNCF-Standard bietet vendor-neutrale Instrumentierung
Die drei Säulen verbinden
Die Säulen werden mächtig, wenn sie verbunden sind. Ein Spike in Fehlermetriken führt Sie zu relevanten Traces. Ein langsamer Trace zeigt auf die spezifischen Logs, die erklären warum. Diese Korrelation transformiert Daten in Einsicht.
Der Schlüssel sind Korrelations-IDs. Jeder Request sollte eine einzigartige Trace-ID tragen, die in allen drei Datentypen erscheint. Wenn etwas fehlschlägt, können Sie dieser ID von einem Metrik-Dashboard zu Traces zu Logs folgen und ein vollständiges Bild dessen aufbauen, was passiert ist.
Observability in der Praxis: Eine DACH-Fallstudie
Eine deutsche E-Commerce-Plattform erlebte intermittierende Checkout-Ausfälle. Ihr Monitoring zeigte gelegentliche Fehlerraten-Spikes, aber sie konnten die Ursache nicht identifizieren. Nach Implementierung ordentlicher Observability:
- Metriken enthüllten, dass Ausfälle mit spezifischen Zahlungsanbieter-Antwortzeiten korrelierten
- Traces zeigten, dass Timeouts nur auftraten, wenn ein Drittanbieter-Betrugserkennungsservice langsam war
- Logs legten offen, dass der Betrugsservice synchrone Geolocation-Lookups machte, die manchmal 30+ Sekunden dauerten
Die Lösung war einfach: Geolocation in asynchrone Verarbeitung verschieben. Ohne Observability, die die Punkte verband, hätten sie den Zahlungsanbieter endlos beschuldigt.
Ihren Observability-Stack aufbauen
Der DACH-Markt bietet mehrere bewährte Ansätze:
Open Source Stack
- Logs: Elasticsearch/OpenSearch + Kibana, oder Loki + Grafana
- Metriken: Prometheus + Grafana, oder InfluxDB
- Traces: Jaeger oder Tempo
- Instrumentierung: OpenTelemetry über alle drei
Kommerzielle Optionen
- Vollständige Plattformen: Datadog, Dynatrace, New Relic, Splunk
- Cloud-native: AWS X-Ray + CloudWatch, Azure Monitor, Google Cloud Trace
Für DACH-Unternehmen mit Datenresidenz-Anforderungen sind selbst gehostete Open Source oder kommerzielle Deployments in EU-Regionen oft obligatorisch.
Häufige Observability-Fallstricke
Alles sammeln
Mehr Daten sind nicht bessere Daten. Jedes Log auf Debug-Level zu speichern wird Ihr Budget sprengen und Ihre Queries verlangsamen. Seien Sie strategisch, was Sie sammeln und wie lange Sie es aufbewahren.
Dashboard-Überladung
Fünfzig Dashboards, die niemand anschaut, bieten null Wert. Bauen Sie Dashboards für spezifische Anwendungsfälle: On-Call-Triage, Kapazitätsplanung, Business-Metriken. Löschen Sie Dashboards, die nicht genutzt werden.
Alert-Müdigkeit
Wenn Ihr Team Alerts ignoriert, weil die meisten False Positives sind, haben Sie gar kein Alerting. Jeder Alert sollte Aktion erfordern. Wenn nicht, sollte es kein Alert sein.
Fehlender Kontext
Logs ohne Korrelations-IDs, Traces ohne Service-Namen, Metriken ohne Labels—alles sind Daten ohne Bedeutung. Investieren Sie in ordentliche Instrumentierung, bevor Sie sich um fancy Visualisierung sorgen.
Ihre Observability-Reise starten
Sie müssen nicht alles auf einmal implementieren. Beginnen Sie mit diesen Prioritäten:
- Neue Services von Tag eins mit OpenTelemetry instrumentieren
- Die vier goldenen Signale zu Ihren kritischsten Services hinzufügen
- Distributed Tracing für Ihre Traffic-intensivsten Pfade implementieren
- Log-Formate mit Korrelations-IDs standardisieren
- Ihre Säulen in einer einzigen Ansicht verbinden
Observability ist kein Tool, das Sie kaufen—es ist eine Fähigkeit, die Sie aufbauen. Das Ziel ist nicht perfekte Sichtbarkeit in alles, sondern ausreichende Einsicht, um Probleme schnell zu debuggen und Systemverhalten über die Zeit zu verstehen.