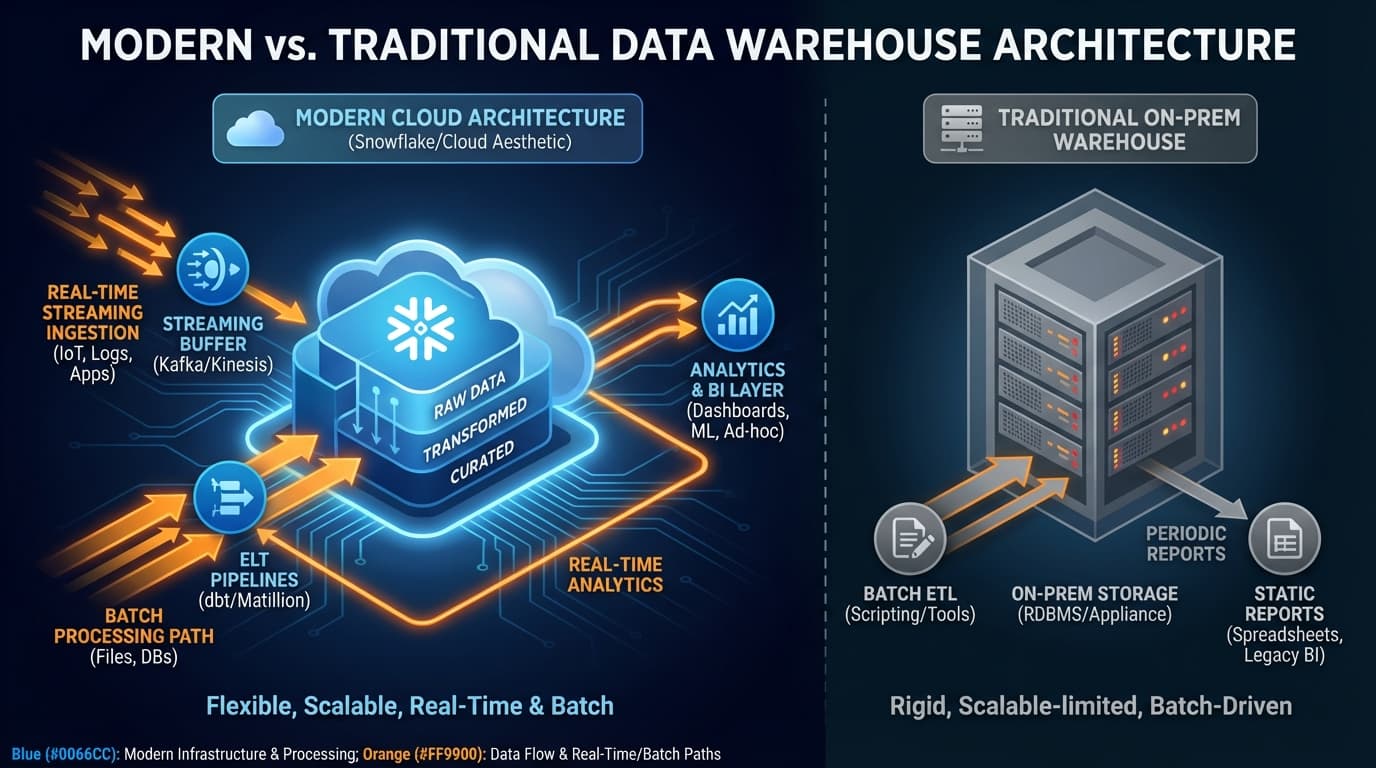
The traditional data warehouse—a monolithic, schema-on-write repository for structured analytics—served enterprises well for decades. But the explosion of data volumes, the demand for real-time insights, and the rise of unstructured data have exposed its limitations. Yet the alternative—dumping everything into a data lake and hoping for the best—created its own problems.
Modern data warehousing isn't about choosing sides. It's about combining the best of multiple paradigms into a coherent architecture that serves diverse analytical needs.
The Evolution of Enterprise Data Architecture
The Traditional Warehouse Era
Classic data warehouses—built on Oracle, Teradata, or SQL Server—excelled at structured analytics. They provided:
- Schema enforcement and data quality guarantees
- ACID transactions and consistency
- Excellent query performance for known patterns
- Strong governance and security
But they struggled with unstructured data, real-time requirements, and the cost of storing ever-growing datasets.
The Data Lake Experiment
Hadoop-based data lakes promised to solve everything: store anything, at any scale, at low cost. Schema-on-read would provide flexibility. The reality was different:
- Data swamps emerged—nobody knew what was in the lake
- Query performance was often poor for interactive analytics
- Governance and security were afterthoughts
- ACID guarantees were absent or complex
A data lake without governance is not a strategic asset—it's an expensive liability.
Modern Architectures: The Best of Both Worlds
Cloud Data Warehouses
Snowflake, Databricks SQL, BigQuery, and Azure Synapse represent a new generation. They combine warehouse semantics with cloud economics:
- Separation of storage and compute: Scale each independently, pay for what you use
- Elastic compute: Spin up massive clusters for heavy workloads, scale down for light queries
- Semi-structured support: Native handling of JSON, XML, and variant data types
- Consumption pricing: No upfront capacity planning
The Lakehouse Pattern
Delta Lake, Apache Iceberg, and Apache Hudi bring warehouse-like reliability to data lakes:
- ACID transactions: Reliable writes, consistent reads
- Schema evolution: Modify schemas without rewriting data
- Time travel: Query data as it existed at any point in history
- Performance optimization: Data skipping, Z-ordering, caching
The lakehouse gives you data lake flexibility with warehouse reliability.
Real-Time Layers
Neither warehouses nor lakes were designed for real-time. Modern architectures add streaming layers:
- Kafka/Event Hubs: Stream ingestion and event processing
- Stream processing: Flink, Spark Streaming, ksqlDB for real-time transformations
- Real-time serving: Materialized views, caches, and specialized databases
Choosing the Right Architecture
There's no universal best architecture. The right choice depends on your specific needs:
Cloud Data Warehouse First
Choose this when:
- Your primary use case is BI and reporting
- Data is primarily structured
- You want the simplest operational model
- Your team has SQL skills but limited big data expertise
Lakehouse First
Choose this when:
- You have diverse data types (structured, semi-structured, unstructured)
- ML/AI workloads are important
- You want to avoid vendor lock-in with open formats
- You have or can build big data engineering expertise
Hybrid Approach
Many enterprises use both:
- Lakehouse for data engineering, ML, and flexible exploration
- Cloud warehouse for governed BI and reporting
- Data sharing between layers as needed
Migration Strategies
Moving from traditional warehouses to modern architectures doesn't happen overnight. Practical approaches:
Parallel Running
Keep the legacy warehouse operational while building the new platform. Migrate workloads incrementally, validate results, cut over when ready.
Strangler Pattern
New data and new use cases go to the modern platform. Existing workloads migrate opportunistically when modified or retired.
Virtual Federation
Use virtualization or federation tools to present a unified view while data lives in multiple places. Migrate the data layer transparently behind the virtualization.
Key Success Factors
Architecture alone doesn't guarantee success. Critical enablers:
- Data modeling discipline: Modern doesn't mean unmodeled. Dimensional models and semantic layers still matter.
- Governance from day one: Catalog, lineage, and quality monitoring aren't optional.
- Performance engineering: Cloud is not magic. Partitioning, clustering, and caching still require thought.
- Cost management: Consumption pricing can explode without controls. Implement FinOps practices.
The Path Forward
Modern data warehousing is not about replacing one technology with another. It's about building an architecture that serves diverse needs—from real-time operational analytics to exploratory data science to governed enterprise reporting.
Need help modernizing your data warehouse architecture? Our team helps DACH enterprises evaluate options, design target architectures, and execute migrations that deliver value without disruption.