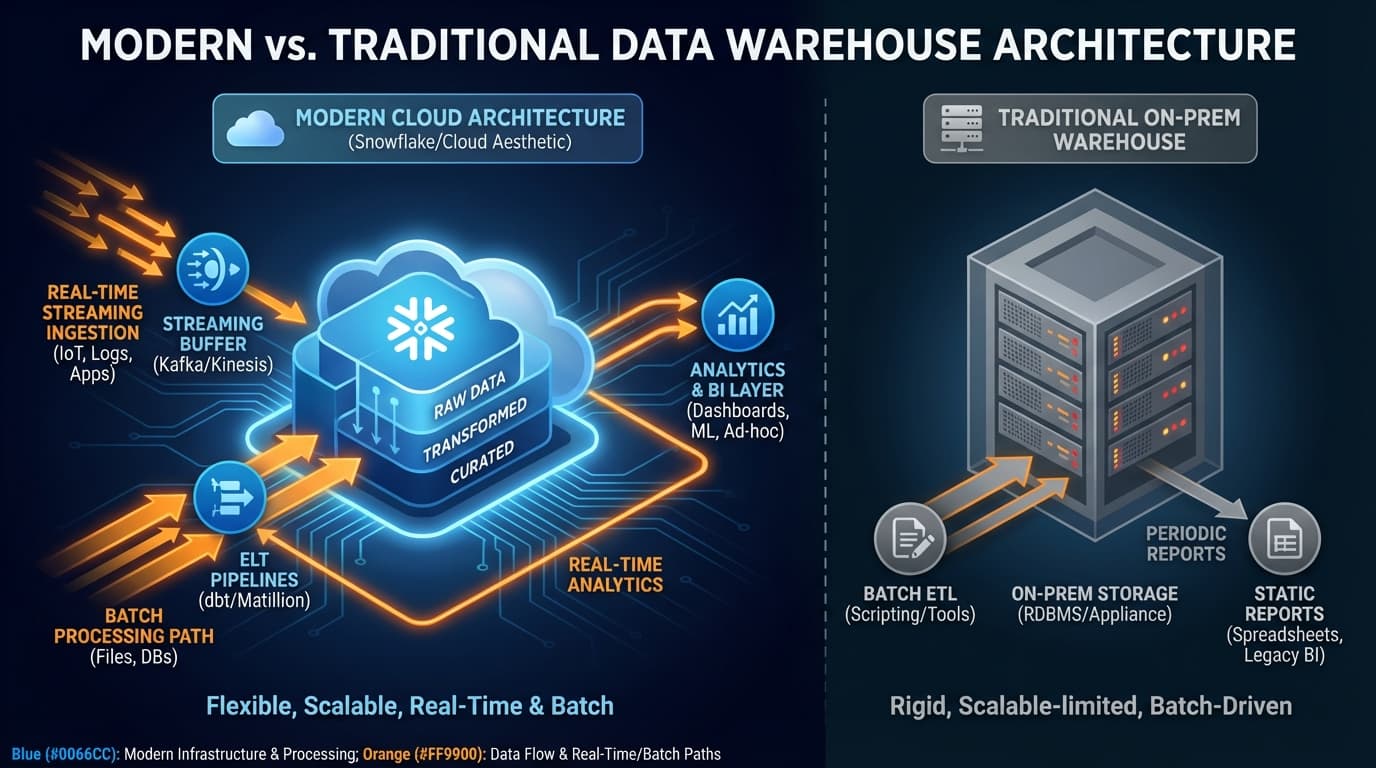
Das traditionelle Data Warehouse—ein monolithisches, Schema-on-Write-Repository für strukturierte Analytics—diente Unternehmen jahrzehntelang gut. Aber die Explosion der Datenvolumen, die Nachfrage nach Echtzeit-Insights und der Aufstieg unstrukturierter Daten haben seine Grenzen aufgezeigt. Doch die Alternative—alles in einen Data Lake zu kippen und auf das Beste zu hoffen—schuf eigene Probleme.
Modernes Data Warehousing bedeutet nicht, Seiten zu wählen. Es geht darum, das Beste aus mehreren Paradigmen in einer kohärenten Architektur zu kombinieren, die diverse analytische Bedürfnisse bedient.
Die Evolution der Enterprise-Datenarchitektur
Die traditionelle Warehouse-Ära
Klassische Data Warehouses—gebaut auf Oracle, Teradata oder SQL Server—glänzten bei strukturierter Analytik. Sie boten:
- Schema-Durchsetzung und Datenqualitätsgarantien
- ACID-Transaktionen und Konsistenz
- Exzellente Abfrage-Performance für bekannte Muster
- Starke Governance und Sicherheit
Aber sie kämpften mit unstrukturierten Daten, Echtzeit-Anforderungen und den Kosten der Speicherung ständig wachsender Datasets.
Das Data-Lake-Experiment
Hadoop-basierte Data Lakes versprachen, alles zu lösen: alles speichern, in jeder Größenordnung, zu niedrigen Kosten. Schema-on-Read würde Flexibilität bieten. Die Realität war anders:
- Datensümpfe entstanden—niemand wusste, was im Lake war
- Abfrage-Performance war oft schlecht für interaktive Analytics
- Governance und Sicherheit waren Nachgedanken
- ACID-Garantien fehlten oder waren komplex
Ein Data Lake ohne Governance ist kein strategisches Asset—es ist eine teure Belastung.
Moderne Architekturen: Das Beste aus beiden Welten
Cloud Data Warehouses
Snowflake, Databricks SQL, BigQuery und Azure Synapse repräsentieren eine neue Generation. Sie kombinieren Warehouse-Semantik mit Cloud-Ökonomie:
- Trennung von Storage und Compute: Jedes unabhängig skalieren, bezahlen Sie, was Sie nutzen
- Elastisches Compute: Massive Cluster für schwere Workloads hochfahren, für leichte Abfragen herunterskalieren
- Semi-strukturierte Unterstützung: Native Behandlung von JSON, XML und Variant-Datentypen
- Verbrauchsbasierte Preise: Keine Vorab-Kapazitätsplanung
Das Lakehouse-Muster
Delta Lake, Apache Iceberg und Apache Hudi bringen Warehouse-ähnliche Zuverlässigkeit zu Data Lakes:
- ACID-Transaktionen: Zuverlässige Schreibvorgänge, konsistente Lesevorgänge
- Schema-Evolution: Schemas modifizieren, ohne Daten neu zu schreiben
- Zeitreisen: Daten abfragen, wie sie zu jedem Zeitpunkt in der Geschichte existierten
- Performance-Optimierung: Data Skipping, Z-Ordering, Caching
Das Lakehouse gibt Ihnen Data-Lake-Flexibilität mit Warehouse-Zuverlässigkeit.
Echtzeit-Schichten
Weder Warehouses noch Lakes wurden für Echtzeit entworfen. Moderne Architekturen fügen Streaming-Schichten hinzu:
- Kafka/Event Hubs: Stream-Ingestion und Event-Verarbeitung
- Stream-Verarbeitung: Flink, Spark Streaming, ksqlDB für Echtzeit-Transformationen
- Echtzeit-Serving: Materialisierte Views, Caches und spezialisierte Datenbanken
Die richtige Architektur wählen
Es gibt keine universell beste Architektur. Die richtige Wahl hängt von Ihren spezifischen Bedürfnissen ab:
Cloud Data Warehouse zuerst
Wählen Sie dies, wenn:
- Ihr primärer Anwendungsfall BI und Reporting ist
- Daten primär strukturiert sind
- Sie das einfachste Betriebsmodell wollen
- Ihr Team SQL-Skills hat, aber begrenzte Big-Data-Expertise
Lakehouse zuerst
Wählen Sie dies, wenn:
- Sie diverse Datentypen haben (strukturiert, semi-strukturiert, unstrukturiert)
- ML/AI-Workloads wichtig sind
- Sie Vendor-Lock-in mit offenen Formaten vermeiden wollen
- Sie Big-Data-Engineering-Expertise haben oder aufbauen können
Hybrid-Ansatz
Viele Unternehmen nutzen beides:
- Lakehouse für Data Engineering, ML und flexible Exploration
- Cloud Warehouse für governiertes BI und Reporting
- Datenaustausch zwischen Schichten nach Bedarf
Migrationsstrategien
Der Umzug von traditionellen Warehouses zu modernen Architekturen passiert nicht über Nacht. Praktische Ansätze:
Parallelbetrieb
Das Legacy-Warehouse betriebsbereit halten, während die neue Plattform aufgebaut wird. Workloads inkrementell migrieren, Ergebnisse validieren, umstellen, wenn bereit.
Strangler-Pattern
Neue Daten und neue Anwendungsfälle gehen zur modernen Plattform. Bestehende Workloads migrieren opportunistisch, wenn sie modifiziert oder ausgemustert werden.
Virtuelle Föderation
Virtualisierungs- oder Föderationstools verwenden, um eine einheitliche Sicht zu präsentieren, während Daten an mehreren Orten leben. Die Datenschicht transparent hinter der Virtualisierung migrieren.
Schlüssel-Erfolgsfaktoren
Architektur allein garantiert keinen Erfolg. Kritische Enabler:
- Datenmodellierungsdisziplin: Modern bedeutet nicht unmodelliert. Dimensionale Modelle und semantische Schichten zählen immer noch.
- Governance von Tag eins: Katalog, Lineage und Qualitätsmonitoring sind nicht optional.
- Performance-Engineering: Cloud ist keine Magie. Partitionierung, Clustering und Caching erfordern immer noch Nachdenken.
- Kostenmanagement: Verbrauchsbasierte Preise können ohne Kontrollen explodieren. Implementieren Sie FinOps-Praktiken.
Der Weg nach vorn
Modernes Data Warehousing bedeutet nicht, eine Technologie durch eine andere zu ersetzen. Es geht darum, eine Architektur aufzubauen, die diverse Bedürfnisse bedient—von Echtzeit-operativer Analytik über explorative Data Science bis zu governiertem Enterprise-Reporting.
Brauchen Sie Hilfe bei der Modernisierung Ihrer Data-Warehouse-Architektur? Unser Team hilft DACH-Unternehmen, Optionen zu evaluieren, Zielarchitekturen zu designen und Migrationen durchzuführen, die Wert ohne Unterbrechung liefern.