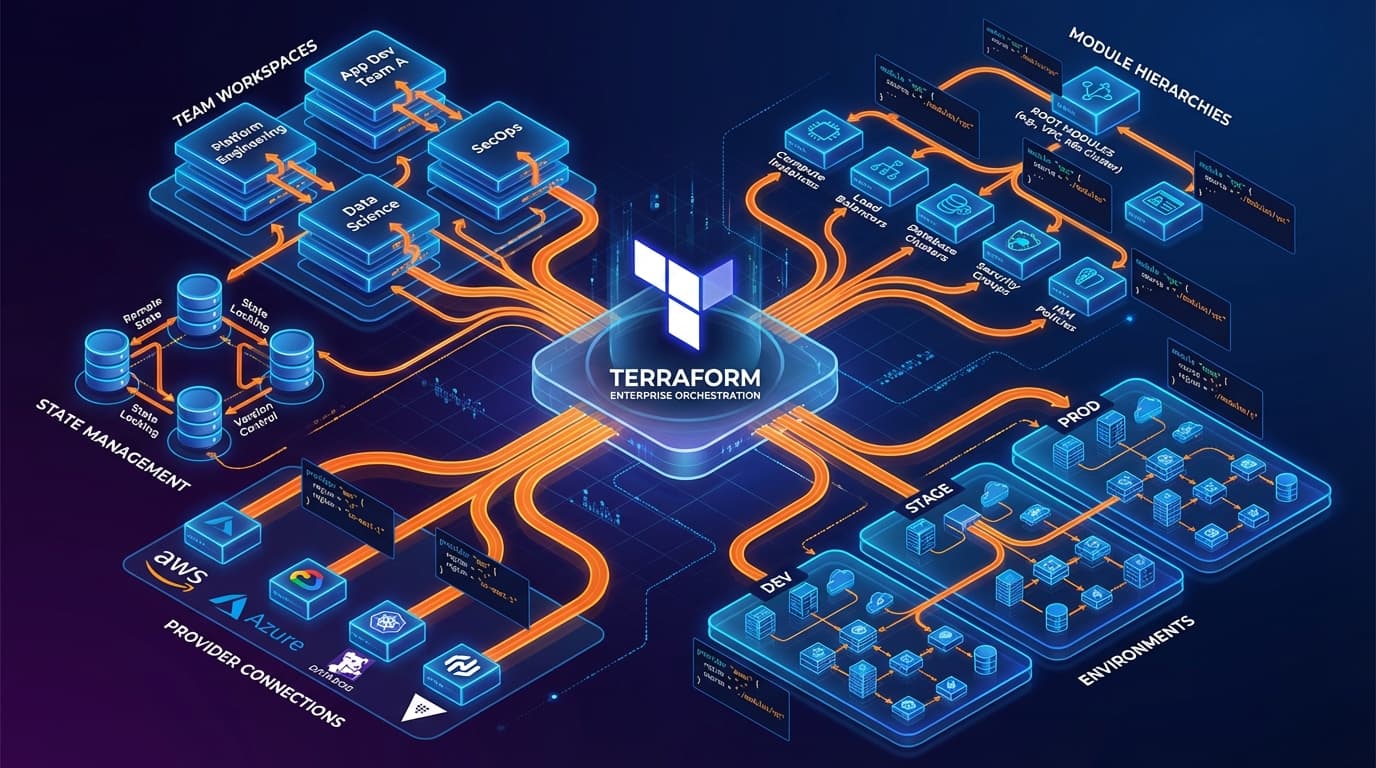
Terraform fängt einfach an. Ein paar Ressourcen, eine einzelne State-Datei, ein Ingenieur, der alles versteht. Dann passiert Erfolg: mehr Teams, mehr Umgebungen, mehr Komplexität. Plötzlich wird dieses einfache Setup zum Engpass. State-File-Locks blockieren Deployments. Änderungen in einem Team brechen ein anderes. Niemand weiß, wem was gehört. So skalieren Sie Terraform, ohne den Verstand zu verlieren.
Die Skalierungs-Herausforderungen
Wenn Organisationen wachsen, trifft Terraform auf vorhersehbare Schmerzpunkte:
- State-File-Konflikte: Großer monolithischer State bedeutet, dass Teams auf Locks warten
- Blast Radius: Ein Fehler in einem Modul kann unzusammenhängende Ressourcen beeinflussen
- Langsame Plans: Terraform muss Tausende von Ressourcen refreshen vor jeder Änderung
- Code-Duplikation: Teams kopieren statt Module zu teilen
- Drift und Inkonsistenz: Manuelle Änderungen akkumulieren, State divergiert von der Realität
Pattern 1: State-Segmentierung
Die wirkungsvollste Änderung ist das Aufteilen Ihres States. Statt einer massiven State-Datei, erstellen Sie logische Grenzen:
Nach Umgebung:
- terraform/environments/dev/
- terraform/environments/staging/
- terraform/environments/prod/
Nach Domäne oder Service:
- terraform/networking/
- terraform/kubernetes/
- terraform/databases/
- terraform/applications/team-a/
Jedes Segment hat seine eigene State-Datei, seinen eigenen Lock und seinen eigenen Blast Radius. Teams können unabhängig deployen. Eine Netzwerkänderung blockiert kein Anwendungs-Deployment.
Cross-State-Referenzen:
Segmentierte State-Dateien müssen Daten teilen. Verwenden Sie terraform_remote_state Data Sources oder, besser, dedizierte Outputs gespeichert in Parameter Store oder Consul. Das schafft klare Schnittstellen zwischen State-Grenzen.
Pattern 2: Modul-Architektur
Module sind Terraforms Wiederverwendungs-Mechanismus, aber schlecht designte Module schaffen mehr Probleme als sie lösen. Hier ist eine Struktur, die skaliert:
Dreistufige Modul-Hierarchie:
- Primitive Module: Dünne Wrapper um einzelne Ressourcen mit sinnvollen Defaults (aws_vpc, aws_rds_instance)
- Composite Module: Kombinieren Primitives zu funktionalen Einheiten (vpc-with-subnets, rds-with-monitoring)
- Service Module: Vollständige Anwendungs-Stacks, die Teams konsumieren (microservice-stack, data-pipeline)
Teams sollten hauptsächlich mit Service-Modulen interagieren. Platform Engineers pflegen die unteren Schichten. Das schafft eine klare Verantwortungsteilung.
Modul-Versionierung:
Jedes Modul sollte versioniert sein. Verwenden Sie semantische Versionierung und eine private Modul-Registry (Terraform Cloud, Artifactory oder S3-basiert). Pinnen Sie Versionen in konsumierendem Code—verwenden Sie niemals unversionierte Source-Referenzen in Produktion.
Pattern 3: Workspace-Strategie
Terraform Workspaces ermöglichen mehrere Instanzen derselben Konfiguration. Verwenden Sie sie für Umgebungs-Promotion, nicht für fundamental unterschiedliche Infrastruktur.
Gute Workspace-Nutzung:
- dev, staging, prod Umgebungen mit gleicher Struktur aber unterschiedlichen Größen
- Regionale Deployments identischer Infrastruktur
- Feature-Branch-Umgebungen für Testing
Schlechte Workspace-Nutzung:
- Komplett unterschiedliche Infrastruktur, die zufällig Code teilt
- Workspaces, die extensive bedingte Logik benötigen
Wenn Sie viele Conditionals basierend auf Workspace brauchen, sind Ihre Konfigurationen zu unterschiedlich zum Teilen—trennen Sie sie in separate Roots.
Pattern 4: Policy as Code
Wenn mehrere Teams Infrastruktur deployen, brauchen Sie Leitplanken. Terraform allein kann keine Sicherheitsrichtlinien, Kostenbeschränkungen oder Compliance-Anforderungen durchsetzen. Fügen Sie Policy as Code hinzu.
Tools für Terraform Policy:
- Sentinel: HashiCorps Policy-Sprache (Terraform Cloud/Enterprise)
- OPA/Rego: Open Policy Agent mit Conftest für Plan-File-Validierung
- Checkov: Statische Analyse für Sicherheits-Fehlkonfigurationen
- tfsec: Security-Scanner für Terraform-Code
Führen Sie Policy-Checks in CI vor Apply aus. Blockieren Sie Merges, die Policies verletzen. Machen Sie Leitplanken automatisch, nicht beratend.
Pattern 5: Automatisierte Pipelines
Manuelles terraform apply skaliert nicht. Bauen Sie automatisierte Pipelines, die Prozesse durchsetzen:
Pipeline-Stufen:
- Validate: terraform validate, Format-Check, Linting
- Security Scan: tfsec, Checkov, custom Policies
- Plan: Plan-File generieren und speichern
- Review: Menschliche Genehmigung für Produktionsänderungen
- Apply: Den geprüften Plan ausführen
- Verify: Post-Apply-Validierung und Drift-Erkennung
GitOps für Terraform:
Behandeln Sie Ihr Terraform-Repository als Single Source of Truth. Änderungen fließen durch Pull Requests. Genehmigte Merges triggern Applies. Atlantis und Terraform Cloud ermöglichen beide diesen Workflow.
Pattern 6: Drift-Management
In Multi-Team-Umgebungen ist Drift unvermeidlich. Jemand macht eine manuelle Änderung. Eine Automatisierung modifiziert Ressourcen außerhalb von Terraform. State divergiert von der Realität.
Drift-Erkennungs-Strategien:
- Geplante Plans: terraform plan regelmäßig ausführen und bei Unterschieden alarmieren
- AWS Config / Azure Policy: Cloud-native Drift-Erkennung
- Driftctl: Open Source Tool für umfassende Drift-Analyse
Drift-Behebung:
- Import: Manuelle Ressourcen unter Terraform-Kontrolle bringen
- Override: Terraform erneut anwenden, um gewünschten State wiederherzustellen
- Accept: Terraform aktualisieren, um Realität zu entsprechen, wenn die Änderung beabsichtigt war
DACH-Enterprise-Überlegungen
Deutsche und europäische Unternehmen haben zusätzliche Anforderungen:
- State-File-Sicherheit: State enthält Secrets—at Rest verschlüsseln, Zugriff beschränken, Reads auditieren
- Audit-Trails: Alle Terraform-Operationen für Compliance loggen
- Change Control: Mit ITSM-Prozessen für Produktionsänderungen integrieren
- Datenresidenz: Sicherstellen, dass State-Backends und Modul-Registries Datenanforderungen erfüllen
Implementierungs-Roadmap
Sie können nicht alles auf einmal fixen. Priorisieren Sie diese Änderungen:
- Woche 1-2: Ihre größten State-Files nach Domäne segmentieren
- Woche 3-4: Basis-CI-Pipeline mit Validierung und Security-Scanning implementieren
- Monat 2: Gemeinsame Patterns in versionierte Module extrahieren
- Monat 3: Policy as Code für kritische Leitplanken hinzufügen
- Fortlaufend: Drift-Erkennung und Behebungs-Workflows implementieren
Erfolg messen
Tracken Sie diese Metriken, um zu wissen, ob Ihre Patterns funktionieren:
- Mean Time to Deploy: Wie lange von Commit zu Produktion?
- Lock-Konflikte: Wie oft warten Teams auf State-Locks?
- Plan-Dauer: Wie lange dauern terraform plan Operationen?
- Rollback-Frequenz: Wie oft reverten Sie Infrastrukturänderungen?
- Drift-Incidents: Wie oft verursacht Drift Produktionsprobleme?
Terraform im großen Maßstab geht nicht um perfekte Infrastructure as Code—es geht darum, Teams zu befähigen, schnell und sicher zu arbeiten. Die Patterns hier schaffen Leitplanken ohne Bürokratie, Sharing ohne Kopplung und Unabhängigkeit ohne Chaos.