Integrationsmuster sind das Vokabular der Enterprise-Architektur. Ohne sie wird jede Integration zu einem individuellen Puzzle. Mit ihnen wenden Sie bewährte Lösungen auf wiederkehrende Probleme an. Hier sind sieben Muster, die in praktisch jeder erfolgreichen Enterprise-Integration vorkommen, die wir entworfen haben—und wann Sie welches verwenden sollten.
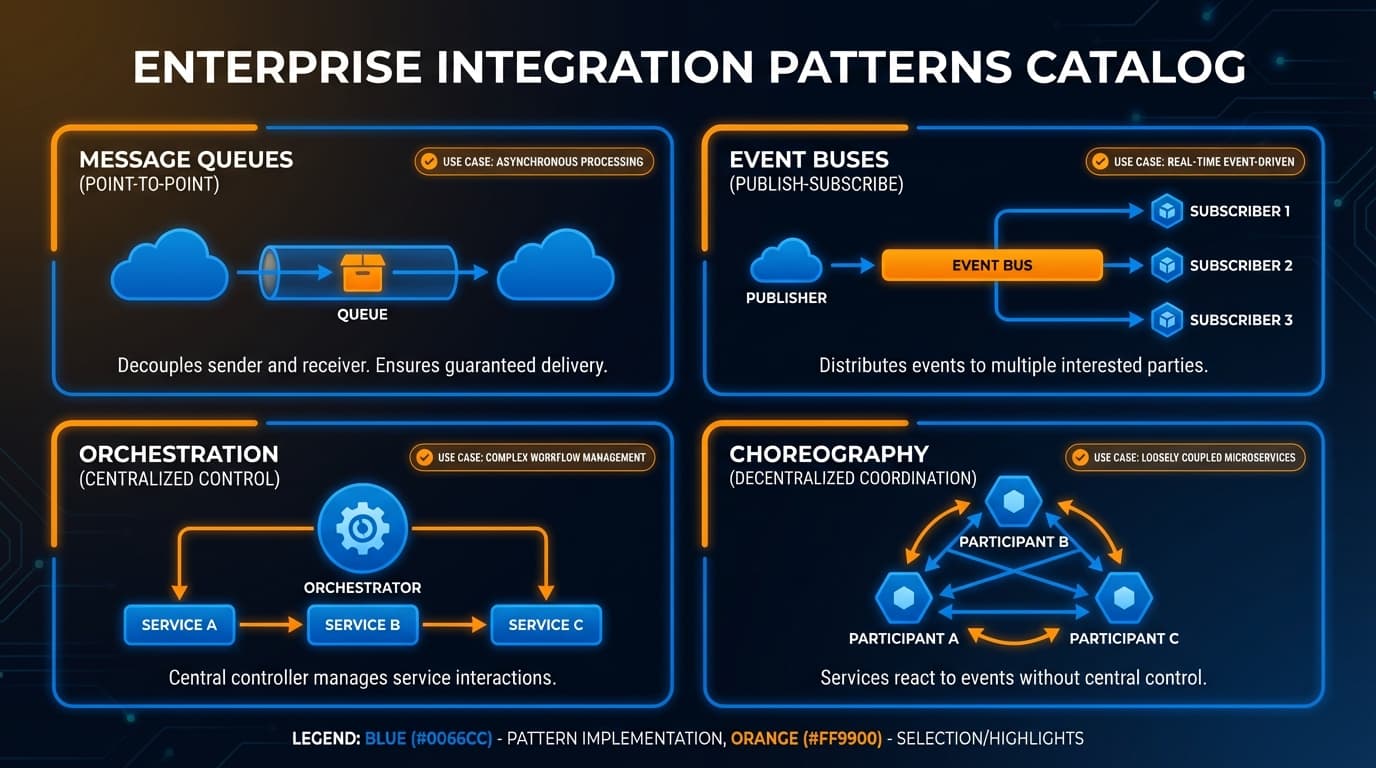
1. Publish-Subscribe (Pub/Sub)
Das Arbeitstier der ereignisgesteuerten Architektur. Publisher senden Events, ohne zu wissen, wer sie konsumiert. Subscriber erhalten Events, für die sie Interesse registriert haben. Diese Entkopplung ist mächtig—Systeme können sich unabhängig entwickeln.
Als ein deutscher Einzelhändler, mit dem wir gearbeitet haben, Pub/Sub für Bestandsaktualisierungen einführte, wechselten sie von koordinierten Deployments über 12 Systeme zu unabhängigen Deployments. Neue Consumer abonnieren, ohne den Publisher zu berühren. Alte Consumer kündigen ohne Zeremonie.
Am besten für:
- Event-Broadcasting: Ein Event, viele Interessenten
- Lose Kopplung: Publisher muss Consumer nicht kennen
- Skalierbarkeit: Subscriber hinzufügen ohne bestehende Systeme zu ändern
Vorsicht bei:
- Nachrichtenreihenfolge: Events können außer der Reihe ankommen
- Doppelte Zustellung: Consumer idempotent gestalten
- Event-Schema-Evolution: Rückwärtskompatibilität planen
2. Request-Reply
Das synchrone Muster, das wir alle kennen. Anfrage senden, auf Antwort warten. Einfach und intuitiv, aber das Warten ist das Problem. Wenn das nachgelagerte System langsam oder nicht verfügbar ist, blockiert der Aufrufer.
Request-Reply funktioniert für Abfragen, die sofortige Antworten benötigen. Es kämpft, wenn Sie mehrere Services verketten—Latenz addiert sich, und jeder Fehler unterbricht die Kette.
Jeder synchrone Aufruf ist eine Wette, dass das nachgelagerte System verfügbar und schnell ist. In verteilten Systemen verliert diese Wette öfter als Ihnen lieb ist.
Am besten für:
- Abfragen: Wenn Sie die Daten wirklich brauchen, bevor Sie fortfahren
- Benutzerorientierte Operationen: Wo sofortiges Feedback erforderlich ist
- Einfache Integrationen: Zwei Systeme, klare Abhängigkeit
3. Message Queue
Entkoppeln Sie Producer von Consumer mit einem Puffer dazwischen. Der Producer sendet Nachrichten an eine Queue; Consumer holen ab, wenn sie bereit sind. Diese zeitliche Entkopplung bewältigt Lastspitzen, ermöglicht Retry-Logik und lässt Systeme in ihrem eigenen Tempo arbeiten.
Eine Schweizer Versicherung verarbeitete Schadensfälle über eine Message Queue, sodass ihr Legacy-Schadensystem mit maximaler Kapazität verarbeiten konnte, während das moderne Frontend Einreichungen mit beliebiger Rate akzeptierte. Spitzenlast? Die Queue absorbiert sie.
Queue-Varianten:
- Point-to-Point: Ein Producer, ein Consumer pro Nachricht
- Competing Consumers: Mehrere Consumer teilen sich die Arbeitslast
- Dead Letter Queue: Fehlgeschlagene Nachrichten landen sichtbar
4. API Gateway
Ein einzelner Einstiegspunkt für alle Client-Anfragen. Das Gateway übernimmt Querschnittsbelange—Authentifizierung, Rate Limiting, Request-Routing, Protokollübersetzung—damit Backend-Services es nicht müssen.
Ohne Gateway implementiert jeder Service seine eigene Security, Monitoring und Throttling. Mit Gateway zentralisieren Sie diese Belange und lassen Services sich auf Geschäftslogik konzentrieren.
Gateway-Verantwortlichkeiten:
- Authentifizierung/Autorisierung: Identität einmal am Edge verifizieren
- Rate Limiting: Backends vor Traffic-Spitzen schützen
- Request-Routing: Traffic an passende Services leiten
- Protokollübersetzung: REST zu gRPC, SOAP zu REST, etc.
- Response-Aggregation: Mehrere Backend-Aufrufe kombinieren
5. Saga Pattern
Verteilte Transaktionen ohne verteilte Locks. Wenn ein Geschäftsprozess mehrere Services umfasst, koordinieren Sagas die Schritte und behandeln Fehler durch kompensierende Aktionen statt Rollbacks.
Betrachten Sie Auftragsverarbeitung: Bestand reservieren, Zahlung belasten, Versand planen. Wenn der Versand fehlschlägt, müssen Sie die Zahlung erstatten und den Bestand freigeben. Sagas machen dies explizit.
In verteilten Systemen können Sie keine atomaren Transaktionen über Services haben. Sagas akzeptieren diese Realität und designen für Eventual Consistency.
Zwei Varianten:
- Choreographie: Jeder Service reagiert auf Events und löst den nächsten Schritt aus
- Orchestrierung: Ein zentraler Koordinator leitet den Workflow
Wann Orchestrierung verwenden:
- Komplexe Workflows mit vielen Schritten
- Bedarf an Sichtbarkeit des Prozessstatus
- Häufige Änderungen der Geschäftslogik
6. Event Sourcing
Events speichern, nicht Zustand. Anstatt einen Datensatz zu aktualisieren, ein Event anhängen, das beschreibt, was passiert ist. Aktueller Zustand wird durch Abspielen der Events abgeleitet. Dieses Muster bietet vollständige Audit-Trails und ermöglicht zeitliche Abfragen.
Ein österreichisches Finanzdienstleistungsunternehmen implementierte Event Sourcing für Regulatory Compliance. Jede Zustandsänderung wird aufgezeichnet. Auditoren können den exakten Zustand zu jedem Zeitpunkt rekonstruieren. Keine "wer hat was wann geändert"-Mysterien.
Vorteile:
- Vollständiger Audit-Trail: Jede Änderung wird aufgezeichnet
- Zeitliche Abfragen: Wie war der Zustand zum Zeitpunkt T?
- Event-Replay: Read-Models neu aufbauen, Bugs rückwirkend beheben
- Debugging: Probleme durch Event-Replay reproduzieren
Herausforderungen:
- Event-Schema-Evolution: Alte Events müssen lesbar bleiben
- Speicherwachstum: Events akkumulieren ewig (by design)
- Abfragekomplexität: Aktueller Zustand erfordert Projektion
7. Backend for Frontend (BFF)
Verschiedene Clients haben verschiedene Bedürfnisse. Mobile Apps wollen minimale Payloads. Web-Apps brauchen reichhaltige Daten. Admin-Interfaces benötigen andere Ansichten. BFF erstellt dedizierte Backends für jeden Client-Typ.
Anstatt einer API, die versucht, allen zu dienen (und niemandem gut dient), lässt BFF jedes Client-Team sein Backend optimieren. Das Mobile-BFF liefert komprimierte, essentielle Daten. Das Web-BFF liefert reichhaltigere Responses.
Wann BFF sinnvoll ist:
- Mehrere Client-Typen: Web, Mobile, IoT, Partner
- Unterschiedliche Optimierungsbedürfnisse: Bandbreite vs. Funktionalität
- Separate Teams: Client-Teams besitzen ihre Backends
Muster kombinieren
Diese Muster schließen sich nicht gegenseitig aus. Echte Architekturen kombinieren sie. Ein API-Gateway routet Anfragen. Manche Anfragen lösen synchrone Queries aus. Andere publizieren Events in eine Message Queue. Sagas koordinieren mehrstufige Prozesse. Event Sourcing pflegt Audit-Trails.
Die Kunst ist zu wissen, welches Muster zu welchem Problem passt. Over-Engineering mit Mustern ist genauso gefährlich wie Under-Engineering ohne sie.
Das richtige Muster wählen
Beginnen Sie mit dem Problem, nicht dem Muster. Was sind die Konsistenzanforderungen? Was ist die akzeptable Latenz? Wie sollen Fehler behandelt werden? Die Antworten leiten die Musterauswahl.
Enterprise-Architekten, die diese Muster beherrschen, bauen nicht nur Integrationen—sie bauen Integrationsfähigkeiten, auf die die Organisation jahrelang vertrauen kann.